Upload Measurement Data and run Analysis#
Now you will post your measurement data and analysis to the database via the API.
You will need to authenticate to the database with your username and password. To make this easy, you can create a file called .env in this folder and complete it with your organization’s URL and authentication information as follows:
dodata_url=https://animal.doplaydo.com
dodata_user=demo
dodata_password=yours
dodata_db=animal.dodata.db.doplaydo.com
dodata_db_user=full_access
dodata_db_password=yours
If you haven’t defined a .env file or saved your credentials to your environment variables, you will be prompted for your credentials now.
import doplaydo.dodata as dd
import pandas as pd
from tqdm.auto import tqdm
from pathlib import Path
import requests
import getpass
from httpx import HTTPStatusError
Let’s now create a project.
In normal circumstances, everyone will be sharing and contributing to a project. In this demo, however, we want to keep your project separate from other users for clarity, so we will append your username to the project name. This way you can also safely delete and recreate projects without creating issues for others. If you prefer though, you can change the PROJECT_ID to anything you like. Just be sure to update it in the subsequent notebooks of this tutorial as well.
username = getpass.getuser()
PROJECT_ID = f"cutback-{username}"
MEASUREMENTS_PATH = Path("6d4c615ff105/")
PROJECT_ID
'cutback-runner'
Lets delete the project if it already exists so that you can start fresh.
try:
dd.project.delete(project_id=PROJECT_ID).text
except HTTPStatusError:
pass
New project#
You can create the project, upload the design manifest, and upload the wafer definitions through the Webapp as well as programmatically using this notebook
Upload Project#
You can create a new project and extract all cells & devices below for the RidgeLoss and RibLoss
The expressions are regex expressions. For intro and testing your regexes you can check out regex101
To only extract top cells set max_hierarchy_lvl=-1 and min_hierarchy_lvl=-1
To disable extraction use a max_hierarchy_lvl < min_hierarchy_lvl
Whitelists take precedence over blacklists, so if you define both, it uses only the whitelist.
cell_extraction = [
dd.project.Extraction(
cell_id="cutback",
cell_white_list=["^cutback_component_add_fiber_array"],
min_hierarchy_lvl=0,
max_hierarchy_lvl=0,
)
]
dd.project.create(
project_id=PROJECT_ID,
eda_file="test_chip.gds",
lyp_file="generic.lyp",
cell_extractions=cell_extraction,
).text
'{"success":18}'
Upload Design Manifest#
The design manifest is a CSV file that includes all the cell names, the cell settings, a list of analysis to trigger, and a list of settings for each analysis.
dm = pd.read_csv("device_table.csv")
dm
| cell | x | y | components | |
|---|---|---|---|---|
| 0 | cutback_loss_2 | 33835 | 116310 | 816 |
| 1 | cutback_loss_1 | 529485 | 116310 | 400 |
| 2 | cutback_loss_0 | 516910 | 714861 | 16 |
dd.project.upload_design_manifest(
project_id=PROJECT_ID, filepath="device_table.csv"
).text
'{"success":200}'
dd.project.download_design_manifest(
project_id=PROJECT_ID, filepath="design_manifest_downloaded.csv"
)
PosixPath('design_manifest_downloaded.csv')
Upload Wafer Definitions#
The wafer definition is a JSON file where you can define the wafer names and die names and location for each wafer.
dd.project.upload_wafer_definitions(
project_id=PROJECT_ID, filepath="wafer_definitions.json"
).text
'{"success":200}'
Upload data#
Your Tester can output the data in JSON files. It does not need to be Python.
You can get all paths which have measurement data within the test path.
data_files = list(MEASUREMENTS_PATH.glob("**/data.json"))
print(data_files[0].parts)
('6d4c615ff105', '-2_0', 'cutback_cutback_loss_2_33835_116310', 'data.json')
You should define a plotting per measurement type in python. Your plots can evolve over time even for the same measurement type.
Required:
- x_name (str): x-axis name
- y_name (str): y-axis name
- x_col (str): x-column to plot
- y_col (list[str]): y-column(s) to plot; can be multiple
Optional:
- scatter (bool): whether to plot as scatter as opposed to line traces
- x_units (str): x-axis units
- y_units (str): y-axis units
- x_log_axis (bool): whether to plot the x-axis on log scale
- y_log_axis (bool): whether to plot the y-axis on log scale
- x_limits (list[int, int]): clip x-axis data using these limits as bounds (example: [10, 100])
- y_limits (list[int, int]): clip y-axis data using these limits as bounds (example: [20, 100])
- sort_by (dict[str, bool]): columns to sort data before plotting. Boolean specifies whether to sort each column in ascending order.
(example: {"wavelegths": True, "optical_power": False})
- grouping (dict[str, int]): columns to group data before plotting. Integer specifies decimal places to round each column.
Different series will be plotted for unique combinations of x column, y column(s), and rounded column values.
(example: {"port": 1, "attenuation": 2})
spectrum_measurement_type = dd.api.device_data.PlottingKwargs(
x_name="wavelength",
y_name="output_power",
x_col="wavelength",
y_col=["output_power"],
)
Upload measurements#
You can now upload measurement data.
This is a bare bones example, in a production setting, you can also add validation, logging, and error handling to ensure a smooth operation.
Every measurement you upload will trigger all the analysis that you defined in the design manifest.
wafer_set = set()
die_set = set()
NUMBER_OF_THREADS = (
dd.settings.n_threads if "127" not in dd.settings.dodata_url else 1
) # for local testing use 1 thread
NUMBER_OF_THREADS
1
if NUMBER_OF_THREADS == 1:
for path in tqdm(data_files):
wafer_id = path.parts[0]
die_x, die_y = path.parts[1].split("_")
r = dd.api.device_data.upload(
file=path,
project_id=PROJECT_ID,
wafer_id=wafer_id,
die_x=die_x,
die_y=die_y,
device_id=path.parts[2],
data_type="measurement",
plotting_kwargs=spectrum_measurement_type,
)
wafer_set.add(wafer_id)
die_set.add(path.parts[2])
r.raise_for_status()
data_files = list(MEASUREMENTS_PATH.glob("**/data.json"))
project_ids = []
device_ids = []
die_ids = []
die_xs = []
die_ys = []
wafer_ids = []
plotting_kwargs = []
data_types = []
for path in data_files:
device_id = path.parts[2]
die_id = path.parts[1]
die_x, die_y = die_id.split("_")
wafer_id = path.parts[0]
device_ids.append(device_id)
die_ids.append(die_id)
die_xs.append(die_x)
die_ys.append(die_y)
wafer_ids.append(wafer_id)
plotting_kwargs.append(spectrum_measurement_type)
project_ids.append(PROJECT_ID)
data_types.append("measurement")
if NUMBER_OF_THREADS > 1:
dd.device_data.upload_multi(
files=data_files,
project_ids=project_ids,
wafer_ids=wafer_ids,
die_xs=die_xs,
die_ys=die_ys,
device_ids=device_ids,
data_types=data_types,
plotting_kwargs=plotting_kwargs,
progress_bar=True,
)
wafer_set = set(wafer_ids)
die_set = set(die_ids)
print(wafer_set)
print(die_set)
print(len(die_set))
{'6d4c615ff105'}
{'1_-2', '-3_-1', '3_-2', '-3_1', '2_-3', '-3_0', '3_-1', '3_1', '2_-2', '-1_-2', '0_3', '0_1', '1_3', '-2_2', '-1_1', '0_-1', '-1_0', '-2_-1', '1_2', '-2_-2', '1_-3', '-3_-2', '-2_3', '1_0', '-1_-3', '-2_-3', '3_0', '0_-3', '-1_2', '1_1', '-3_2', '2_0', '0_0', '3_2', '-1_-1', '-2_0', '2_2', '-1_3', '0_2', '-2_1', '2_3', '0_-2', '1_-1', '2_-1', '2_1'}
45
Analysis#
You can run analysis at 3 different levels. For example to calculate:
Device: averaged power envelope over certain number of samples.
Die: fit the propagation loss as a function of length.
Wafer: Define the Upper and Lower Spec limits for Known Good Die (KGD)

To upload custom analysis functions to the DoData server, follow these simplified guidelines:
Input:
Begin with a unique identifier (device_data_pkey, die_pkey, wafer_pkey) as the first argument.
Add necessary keyword arguments for the analysis.
Output: Dictionary
output: Return a simple, one-level dictionary. All values must be serializable. Avoid using numpy or pandas; convert to lists if needed.
summary_plot: Provide a summary plot, either as a matplotlib figure or io.BytesIO object.
attributes: Add a serializable dictionary of the analysis settings.
device_data_pkey/die_pkey/wafer_pkey: Include the used identifier (device_data_pkey, die_pkey, wafer_pkey).
Die analysis#
You can either trigger analysis automatically by defining it in the design manifest, using the UI or using the Python DoData library.
from IPython.display import Code, display, Image
import doplaydo.dodata as dd
display(Code(dd.config.Path.analysis_functions_die_cutback))
"""Calculates loss per component."""
from typing import Any
import numpy as np
from matplotlib import pyplot as plt
import doplaydo.dodata as dd
def run(
die_pkey: int, key: str = "components", convert_to_dB: bool = False
) -> dict[str, Any]:
"""Returns component loss in dB/component.
Args:
die_pkey: pkey of the die to analyze.
key: attribute key to filter by.
convert_to_dB: if True, convert to dB.
"""
device_data_objects = dd.get_data_by_query(
[
dd.Die.pkey == die_pkey,
]
)
if not device_data_objects:
raise ValueError(f"No device data found with die_pkey {die_pkey}, key {key!r}")
powers = []
components = []
for device_data, df in device_data_objects:
if not device_data.device.cell.attributes.get(key):
raise ValueError(
f"No attribute {key!r} found for die_pkey {die_pkey}, device_pkey {device_data.device.pkey}"
)
components.append(device_data.device.cell.attributes.get(key))
power = df.output_power.max()
power = 10 * np.log10(power) if convert_to_dB else power
powers.append(power)
p = np.polyfit(components, powers, 1)
component_loss = -p[0]
if np.isnan(component_loss):
raise ValueError(
f"Component loss is NaN for {die_pkey=}. {powers=}, is {convert_to_dB=} correct?"
)
fig = plt.figure()
plt.plot(components, powers, "o")
plt.plot(components, np.polyval(p, components), "r-", label="fit")
plt.xlabel("Number of components")
plt.ylabel("Power (dBm)")
plt.title(f"loss = {component_loss:.2e} dB/component")
return dict(
output={"component_loss": component_loss},
summary_plot=fig,
die_pkey=die_pkey,
)
if __name__ == "__main__":
d = run(768)
print(d["output"]["component_loss"])
You can easily get a die primary key to try your device analsys:
device_data, df = dd.get_data_by_query([dd.Project.project_id == PROJECT_ID], limit=1)[
0
]
die_pkey = device_data.die.pkey
die_pkey
624
analysis_function_id = "die_cutback"
response = dd.api.analysis_functions.validate(
analysis_function_id=analysis_function_id,
function_path=dd.config.Path.analysis_functions_die_cutback,
test_model_pkey=die_pkey,
target_model_name="die",
parameters=dict(key="components"),
)
Headers({'server': 'nginx/1.22.1', 'date': 'Fri, 28 Feb 2025 20:57:29 GMT', 'content-type': 'image/png', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', '_output': '{"component_loss": 0.10377506813869435}', '_attributes': '{}', '_die_pkey': '624', 'strict-transport-security': 'max-age=63072000'})
Image(response.content)
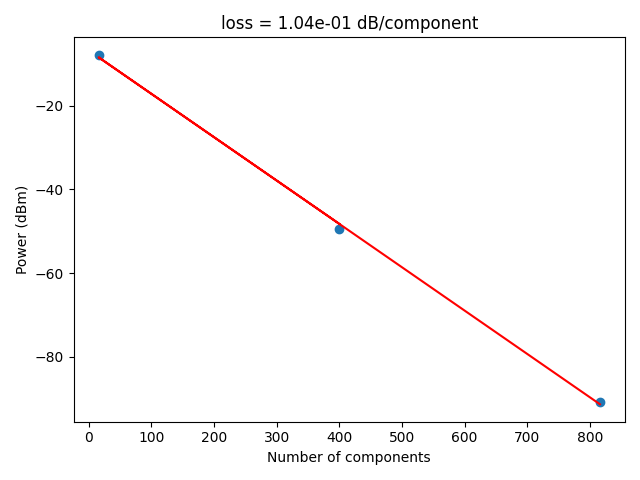
response = dd.api.analysis_functions.validate_and_upload(
analysis_function_id=analysis_function_id,
function_path=dd.config.Path.analysis_functions_die_cutback,
test_model_pkey=die_pkey,
target_model_name="die",
)
Headers({'server': 'nginx/1.22.1', 'date': 'Fri, 28 Feb 2025 20:57:30 GMT', 'content-type': 'image/png', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', '_output': '{"component_loss": 0.10377506813869435}', '_attributes': '{}', '_die_pkey': '624', 'strict-transport-security': 'max-age=63072000'})
parameters = [{"key": "components"}]
dd.analysis.trigger_die_multi(
project_id=PROJECT_ID,
analysis_function_id=analysis_function_id,
wafer_ids=wafer_set,
die_xs=die_xs,
die_ys=die_ys,
parameters=parameters,
progress_bar=True,
n_threads=2,
)
plots = dd.analysis.get_die_analysis_plots(
project_id=PROJECT_ID, wafer_id=wafer_ids[0], die_x=0, die_y=0
)
wafer_id
'6d4c615ff105'
PROJECT_ID
'cutback-runner'
len(plots)
1
for plot in plots:
display(plot)
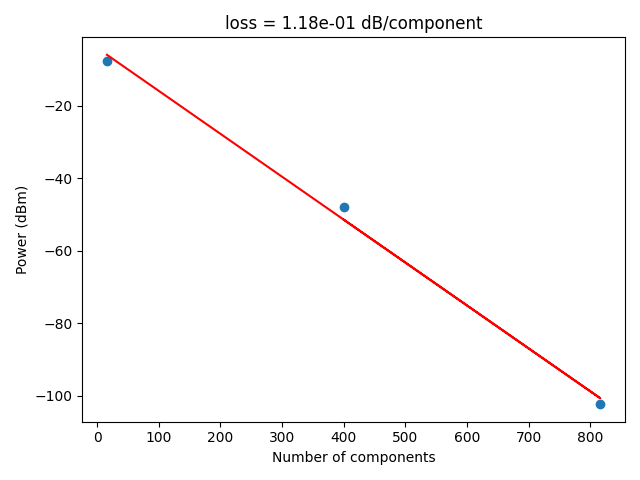
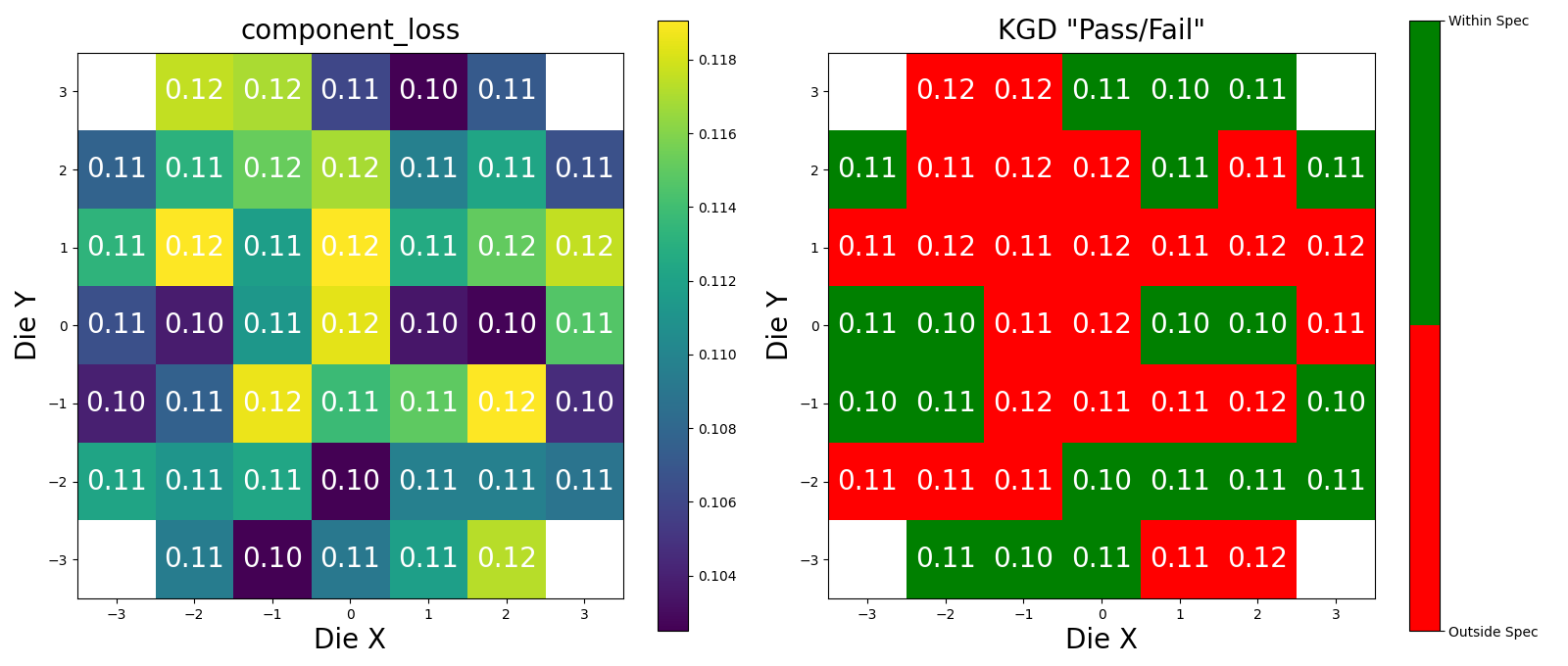
Wafer Analysis#
Lets Define the Upper and Lower Spec limits for Known Good Die (KGD).
Lets find a wafer primary key for this project, so that we can trigger the die analysis on it.
device_data, df = dd.get_data_by_query([dd.Project.project_id == PROJECT_ID], limit=1)[
0
]
wafer_pkey = device_data.die.wafer.pkey
wafer_pkey
21
parameters = {
"key": "components",
"upper_spec": 0.11,
"lower_spec": 0,
"analysis_function_id": "die_cutback",
"metric": "component_loss",
}
response = dd.api.analysis_functions.validate(
analysis_function_id="wafer_loss_cutback",
function_path=dd.config.Path.analysis_functions_wafer_loss_cutback,
test_model_pkey=wafer_pkey,
target_model_name="wafer",
parameters=parameters,
)
Image(response.content)
Headers({'server': 'nginx/1.22.1', 'date': 'Fri, 28 Feb 2025 20:57:44 GMT', 'content-type': 'image/png', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', '_output': '{"losses": [0.11130458572696567, 0.10776089323559161, 0.11264800786632408, 0.11729423599701738, 0.11114541374448252, 0.11330065513565034, 0.10268645601708547, 0.11232297613694042, 0.11183832028400957, 0.10245463309351778, 0.11460668539131803, 0.10347984891886056, 0.10657699809310345, 0.10764381998170555, 0.1175301485223926, 0.10971869771517703, 0.10887368913910549, 0.11381901520278374, 0.11315413692380219, 0.10602550019577736, 0.11696635568997502, 0.10972176972685473, 0.11857772812662098, 0.11947221219884513, 0.11522135909569814, 0.11688427560043592, 0.11219739262247788, 0.1117639498180294, 0.12021317221311953, 0.10718179215223417, 0.11919699824987244, 0.10943731979361485, 0.1046362330289559, 0.1122152580251418, 0.10662144272289341, 0.10377506813869435, 0.10116914628454773, 0.10915857024745343, 0.1023853020999469, 0.11496784183980434, 0.11511215396052463, 0.10397711641889883, 0.10970550645979486, 0.11842111327605227, 0.11755650891327604]}', '_attributes': '{}', '_wafer_pkey': '21', 'strict-transport-security': 'max-age=63072000'})
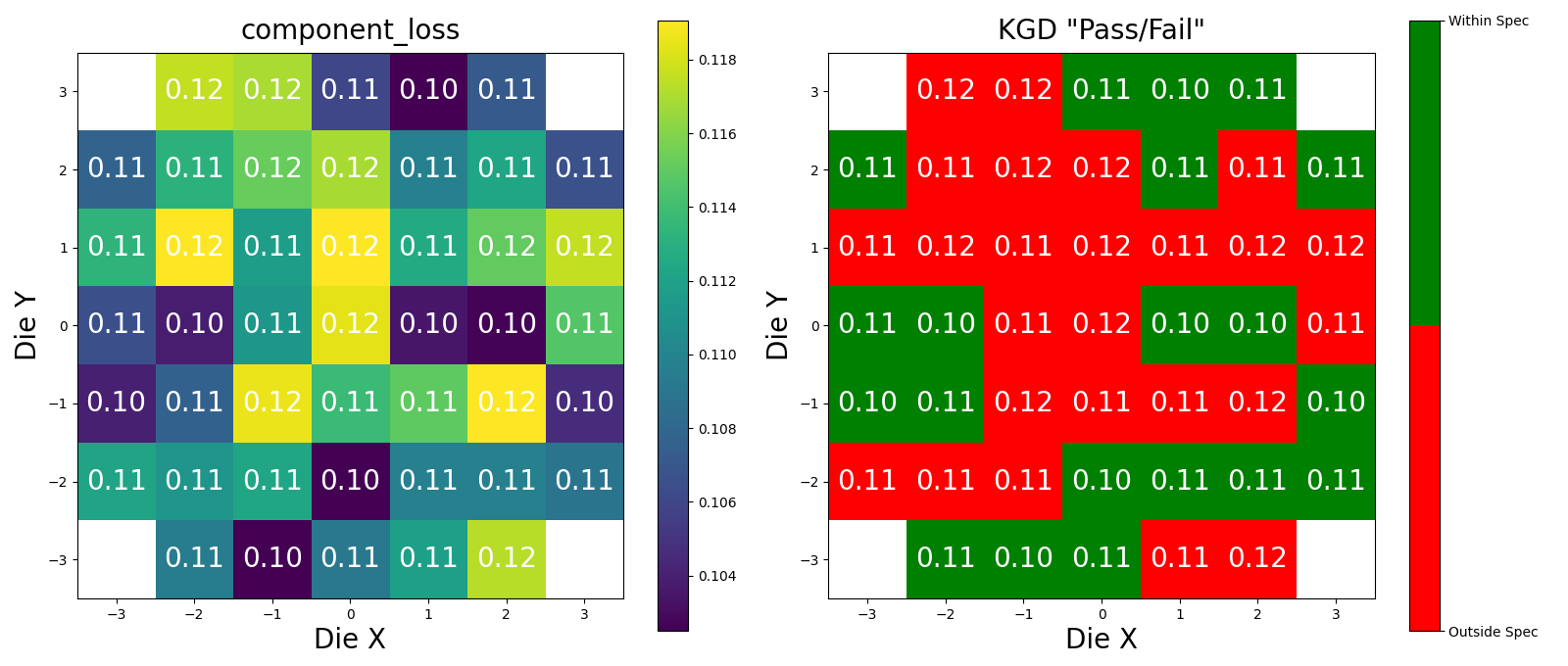
response = dd.api.analysis_functions.validate_and_upload(
analysis_function_id="wafer_loss_cutback",
function_path=dd.config.Path.analysis_functions_wafer_loss_cutback,
test_model_pkey=wafer_pkey,
target_model_name="wafer",
parameters=parameters,
)
Headers({'server': 'nginx/1.22.1', 'date': 'Fri, 28 Feb 2025 20:57:45 GMT', 'content-type': 'image/png', 'transfer-encoding': 'chunked', 'connection': 'keep-alive', '_output': '{"losses": [0.11130458572696567, 0.10776089323559161, 0.11264800786632408, 0.11729423599701738, 0.11114541374448252, 0.11330065513565034, 0.10268645601708547, 0.11232297613694042, 0.11183832028400957, 0.10245463309351778, 0.11460668539131803, 0.10347984891886056, 0.10657699809310345, 0.10764381998170555, 0.1175301485223926, 0.10971869771517703, 0.10887368913910549, 0.11381901520278374, 0.11315413692380219, 0.10602550019577736, 0.11696635568997502, 0.10972176972685473, 0.11857772812662098, 0.11947221219884513, 0.11522135909569814, 0.11688427560043592, 0.11219739262247788, 0.1117639498180294, 0.12021317221311953, 0.10718179215223417, 0.11919699824987244, 0.10943731979361485, 0.1046362330289559, 0.1122152580251418, 0.10662144272289341, 0.10377506813869435, 0.10116914628454773, 0.10915857024745343, 0.1023853020999469, 0.11496784183980434, 0.11511215396052463, 0.10397711641889883, 0.10970550645979486, 0.11842111327605227, 0.11755650891327604]}', '_attributes': '{}', '_wafer_pkey': '21', 'strict-transport-security': 'max-age=63072000'})
for wafer_id in tqdm(wafer_set):
r = dd.analysis.trigger_wafer(
project_id=PROJECT_ID,
wafer_id=wafer_id,
analysis_function_id="wafer_loss_cutback",
parameters=parameters,
)
if r.status_code != 200:
raise requests.HTTPError(r.text)
plots_wafer = dd.analysis.get_wafer_analysis_plots(
project_id=PROJECT_ID, wafer_id=wafer_ids[0], target_model="wafer"
)
len(plots_wafer)
1
set(wafer_ids)
{'6d4c615ff105'}
for plot in plots_wafer:
display(plot)